Qt+Windows-Plate Recognition
前言:
车牌识别系统是现代智能交通系统中的重要组成部分之一,应用十分广泛并随着技术的发展日趋完善。它是以数字图像处理、模式识别、计算机视觉等技术为基础,对摄像头所拍摄的车辆图像或者视频序列进行分析得到每一辆汽车唯一的车牌号码,从而完成识别过程。从技术角度来说,汽车牌照自动识别技术是车牌识别系统的核心。
QW-PR是基于QT平台开发的中文民用汽车牌照定位、识别的Windows版本应用程序。Opencv算法是其核心。本篇主要介绍其开发要点及部分技术细节。对于一些算法和处理过程本篇都会有详细的介绍,并利于代码维护、更新以及迅速读懂程序。
关于车牌识别系统,网上有很多开源的代码比如EasyPR、OpenALPR等。开源程序充分体现了资源的共享性,QW-PR也是其中的受益者同时也希望会对识别小白是施益者,本篇将会以博客叙述的方式来说明。下面即介绍具体步骤。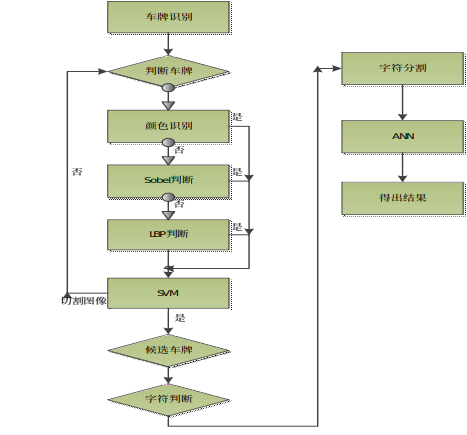
1.1 车牌粗定位
关于车牌定位,方法有很多,所以一个鲁棒性较强的算法可以体现其能力。较传统的方法是对整幅图像做数字图像处理然后再提取感兴趣区域。此种方法类似于将一幅图像地图化。我们要做的就是如何划分地图,并从地图上找到想要得到的区域。我们用的是Sobel算子方法;其次由于部分车牌与车身颜色是有区别的所以我们加入了车牌颜色定位法;另外Opencv提供了很多机器学习模型,我们用到了训练联级分类器来定位感兴趣区域。
1.1.1Sobel 算子法
1.1.1.1 高斯模糊(Gaussian Blur)
图像处理中的模糊有很多种,其中有一种叫做高斯模糊(Gaussian Blur),即是正态分布用在了图像处理中。这种数据平滑技术可用在多种场合,其中数字图像处理则更直观的体现了其用处。
模糊可以形象的理解为每一个像素都取周边像素的平均值。在数值上这是一种平滑,在图像中可令中间点失去细节,则造成了一种模糊的效果。模糊半径越大造成的效果越明显。
既然每一个像素都取平均值,分配权重则成为一个重要的合理性判断标准。显然加权平均要比简单平均好些。我们用到正态分布模式来分配权重。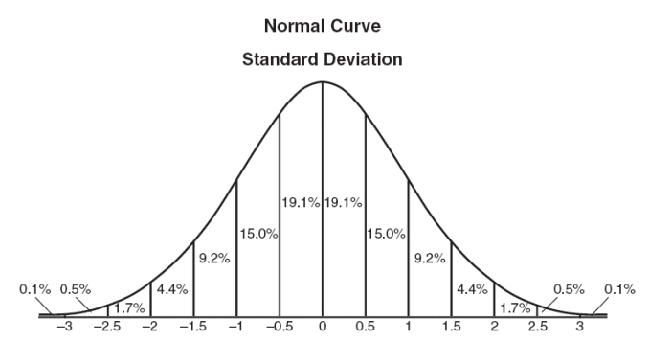
图1.1一维的正态分布
计算平均值的时候,我们只需要将”中心点”作为原点,其他点按照其在正态曲线上的位置,分配权重,就可以得到一个加权平均值。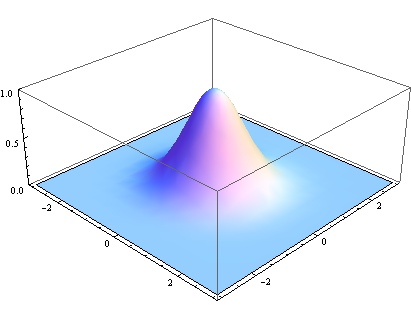
图1.2 二维的正态分布
高斯函数的一维形式为:f(x)=ae$$\frac{-(x-b)^2}{2c^}$$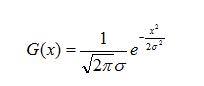
μ是x的均值,σ是x的方差。因为计算平均值的时候,中心点就是原点,所以μ等于0。
二维高斯函数: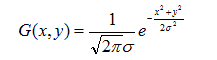
通过这个函数即可计算每一个点的权重。
为了计算权重矩阵,需要设定σ的值。假定σ=1.5,则模糊半径为1的权重矩阵如下: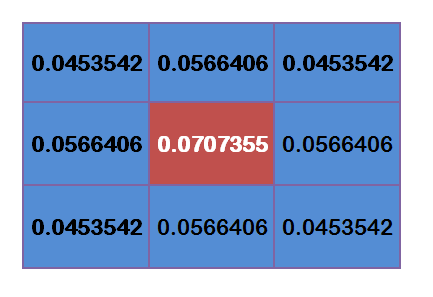
图 1.3
这9个点的权重总和等于0.4787147,如果只计算这9个点的加权平均,还必须让它们的权重之和等于1,因此上面9个值还要分别除以0.4787147,得到最终的权重矩阵: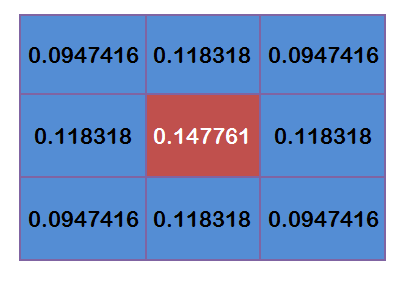
图 1.4
有了权重矩阵,就可以计算高斯模糊的数值了。假设现有9个像素点,灰度值(0—255)如下:
图 1.5
每个点乘以自己的权重值: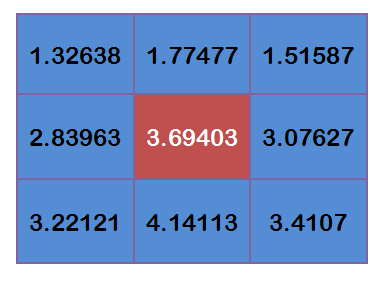
图 1.6
将这9个值加起来就是中心点的高斯模糊值,对所有点重复这个过程就可得到高斯模糊后的图像了。那么有问题了,如果一个点处于边界,如何操作?一个方法就是把已有的点复制到另一面的对应位置,然后再用此方法得出此点的均值。
关于为什么要用到高斯模糊
(1) 便于后续图像的边缘检测处理;
(2) 便于后续车牌判断,因为如果没有此步骤,后选车牌将会大大增加,会增大判断难度。
1.1.1.2 灰度化(gray)
图像的灰度化单单对计算机而言要比彩色图像信息处理要简单,而且后面用到的Opencv的Sobel算子输入图像也必须是灰度化的。虽然此步骤会令图像失去部分信息,但要保证Sobel的输入必须用到此步骤。
1.1.1.3 Sobel算子(Sobel operator)
即垂直边缘检测,此算法的核心。边缘(edge)是指图像局部强度变化最显著的部分。主要存在于目标与目标、目标与背景、区域与区域(包括不同色彩)之间,是图像分割、纹理特征和形状特征等图像分析的重要基础。图像的边缘有方向和幅度两个属性,沿边缘方向像素变化平缓,垂直于边缘方向像素变化剧烈.边缘上的这种变化我们可以用微分算子检测出来,通常用一阶或二阶导数来检测边缘。
该算子包含两组3x3的矩阵,分别为横向和纵向,将之与图像作平面卷积[ 卷积:简单来说就是对周边值加权求和,权值称为卷积模板。
通过卷积模板,原始图像红色的像素点原本是5的值,经过卷积计算即可分别得出横向及纵向的亮度差分近似值。如果以A代表原始图像,Gx及Gy分别代表经横向及纵向边缘检测的图像,其公式如下: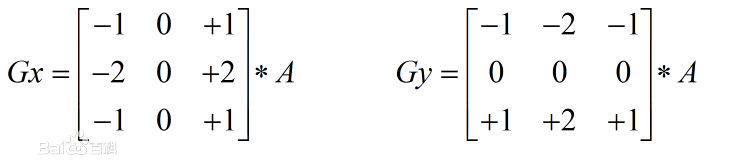
图 1.7
在Opencv 的Sobel中有两个常量SOBEL_X_WEIGHT与SOBEL_Y_WEIGHT代表水平方向和垂直方向的权值,默认前者是1,后者是0,代表仅仅做水平方向求导,而不做垂直方向求导。这样做的意义是,如果我们做了垂直方向求导,会检测出很多水平边缘。水平边缘多也许有利于生成更精确的轮廓,但是由于有些车子前端太多的水平边缘了,例如车头排气孔,标志等等,很多的水平边缘会误导我们的连接结果,导致我们得不到一个恰好的车牌位置。关于更详细的Sobel算子请查看“Opencv函数手册”,里面有较详细的介绍。下面给出部分代码:
Mat sobel;
Mat grad_x, grad_y;
Mat abs_grad_x, abs_grad_y;
Sobel(gray,grad_x,CV_32F,1,0,3,1,0,BORDER_DEFAULT );
convertScaleAbs(grad_x,abs_grad_x);
Sobel(gray,grad_y,CV_32F,0,1,3,1,0,BORDER_DEFAULT );
convertScaleAbs(grad_y,abs_grad_y);
addWeighted(abs_grad_x,0.5,abs_grad_y,0.5,0,sobel);
1.1.1.4 二值化(Binarization)
顾名思义,就是对每一个灰度像素设定一个阈值,高于此阈值的置为255,低于此阈值的置为0。Opencv中的二值化函数可以加上一个自适应阈值参数:
CV_THRESH_OTSU+CV_THRESH_BINARY
我们可以直接使用。局部自适应阈值则是根据像素的邻域块的像素值分布来确定该像素位置上的二值化阈值。这样做的好处在于每个像素位置处的二值化阈值不是固定不变的,而是由其周围邻域像素的分布来决定的。亮度较高的图像区域的二值化阈值通常会较高,而亮度较低的图像区域的二值化阈值则会相适应地变小。不同亮度、对比度、纹理的局部图像区域将会拥有相对应的局部二值化阈值。常用的局部自适应阈值有:1)局部邻域块的均值;2)局部邻域块的高斯加权和。关于Opencv中更详细的二值化介绍请参照“Opencv函手册”。
1.1.1.5 闭运算(Close operation)
即将车牌部分连成一个连通区域,便于后面的检测、提取操作。
有闭操作就有相应的开操作。开操作就是对图像先腐蚀,再膨胀而闭操作是对图像先膨胀,再腐蚀。关于图像的腐蚀膨胀,这里不再做描述。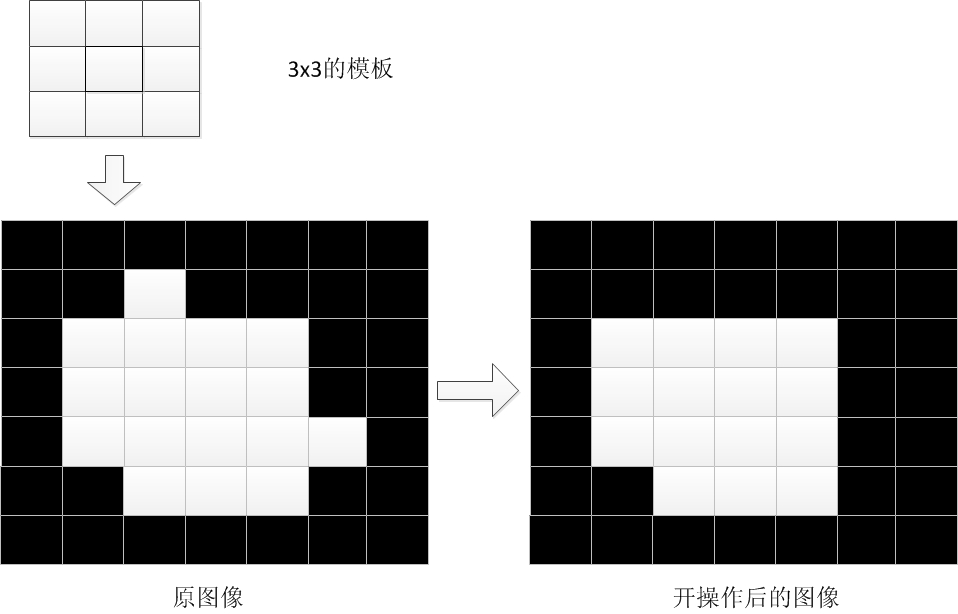
图 1.8 开操作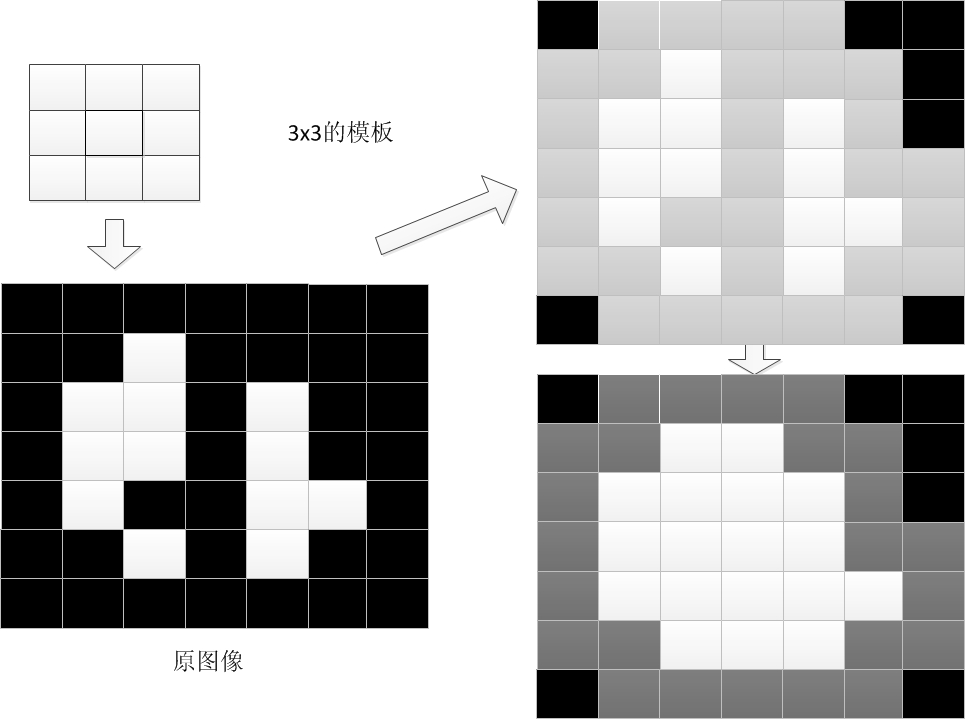
图 1.9 闭操作
Opencv中的闭操作为我们提供了函数:
Mat element = getStructuringElement(MORPH_RECT,Size(18,3)); //宽度推荐18或18+
morphologyEx(two_value,two_value,MORPH_CLOSE,element);
矩形模板宽度在代码中有注释:推荐18或18+。更多的函数相关请查看“Opencv函数手册”。
1.1.1.6 取轮廓(Contour)
即将连通域的外轮廓画出来,便于形成矩形区域并尺寸判断。
我们用到的函数是findContours();
1.1.1.7 尺寸判断(Size judgment)
尺寸判断中我们使用自己的函数:judgementsize();
float error = m_error;
float aspect = m_aspect;
int min= 44*14*m_verifyMin; // minimum area
int max= 44*14*m_verifyMax; // maximum area
float rmin= aspect-aspect*error;
float rmax= aspect+aspect*error;
int area= mr.size.height * mr.size.width;
float r = (float)mr.size.width / (float)mr.size.height;
if(r < 1)
{
r= (float)mr.size.height / (float)mr.size.width;
}
if(( area < min || area > max ) || ( r < rmin || r > rmax ))
{
return false;
}
else
{
return true;
}由于图像近景远景的影响,车牌的大小也会不一。我们定义最大尺寸为4414200最小尺寸为 44141。
此处把面积和宽高比作为尺寸判断的两个标准。
1.1.1.8 角度判断(Angle judgment)
角度判断有两方面的标准:
(1) 判断此矩形大于某一角度则认为不是车牌。
(2) 小角度偏斜扭转为正车牌矩形。
这里特别说明一下偏斜与倾斜不是一个概念,偏斜在矩形框定中正视角仍然是一个矩形,只不过有一定偏斜;而倾斜则在矩形框定中正视角是一个平行四边形。
1.1.1.9 大小归一化(normalization)
即得令到的是尺寸大小相同的候选车牌。为下一步的SVM判断处理提供一个统一模板。同时也为训练数据集提供了样本。
以上即为Sobel方法提取候选车牌的简要介绍,我们在QW-PR中使用了三种方法来提取后选车牌分别是 Sobel方法、颜色判断法、LBP检测法。下面我们来介绍第二种方法:“颜色判断法”。关于这几种方法的顺序优先级,在介绍完提取候选车牌后会详细介绍。
1.1.2 颜色定位法
由于Sobel方法的局限性,会导致很多车牌不能很好检测出并由于用到灰度化,使原本带有颜色信息的图像少了一定的信息量,同时也不很好的符合我们人类判断的标准。因此我们引入了颜色判断的方法来提取候选车牌。
1.1.2.1 颜色空间
我们使用HSV模型而不是RGB模型。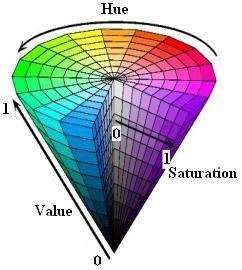
图2.0 HSV模型
色调(H)、饱和度(S)、亮度(V)
H分量是代表颜色特性的分量,用角度度量,取值范围为0~360,从红色开始按逆时针方向计算,红色为0,绿色为120,蓝色为240。S分量代表颜色的饱和信息,取值范围为0.0~1.0,值越大,颜色越饱和。V分量代表明暗信息,取值范围为0.0~1.0,值越大,色彩越明亮。
H分量是HSV模型中唯一跟颜色本质相关的分量。只要固定了H的值,并且保持S和V分量不太小,那么表现的颜色就会基本固定。为了判断蓝色车牌颜色的范围,可以固定了S和V两个值为1以后,调整H的值,然后看颜色的变化范围。通过一段摸索,可以发现当H的取值范围在200到280时,这些颜色都可以被认为是蓝色车牌的颜色范畴。于是我们可以用H分量是否在200与280之间来决定某个像素是否属于蓝色车牌。黄色车牌也是一样的道理,通过观察,可以发现当H值在30到80时,颜色的值可以作为黄色车牌的颜色。
1.1.2.2 步骤
我们将颜色空间从RGB转换到HSV;
依次遍历图像的所有像素,当H值落在200-280之间并且S值与V值也落在0.35-1.0之间,标记为白色像素,否则为黑色像素;
于是对仅有白黑两个颜色的二值图参照原先车牌定位中的方法,使用闭操作,取轮廓等方法将车牌的外接矩形截取出来做进一步的处理。具体细节请查看代码colorlocation.cpp。
当我们遇到蓝车蓝牌或黄车黄牌的时候颜色判断则不能很好的将车牌区分出来,这时我们再结合Sobel算子法提高准确度。简单测试的时候我发现黄色车牌在对比度较暗的情况下比蓝色车牌识别准确率要高。
由于人脸检测算法日渐趋于完善,Opencv也提供了相应函数以及训练好的xml文件。于是想到一种用LBP特征算法来进一步提高车牌检测成功率。下面将详细介绍第三种方法:“LBP特征检测法”。
1.1.3 LBP特征检测法
LBP指局部二值模式,英文全称:Local Binary Pattern,是一种用来描述图像局部特征的算子,LBP特征具有灰度不变性和旋转不变性等显著优点。它是由T. Ojala, M.Pietikäinen, 和 D. Harwood在1994年提出,由于LBP特征计算简单、效果较好,因此LBP特征在计算机视觉的许多领域都得到了广泛的应用,LBP特征比较出名的应用是用在目标检测中,在计算机视觉开源库OpenCV中有使用LBP特征进行人脸识别的接口,也有用LBP特征训练目标检测分类器的方法,Opencv实现了LBP特征的计算,但没有提供一个单独的计算LBP特征的接口。
1.1.3.1 定义
描述方式: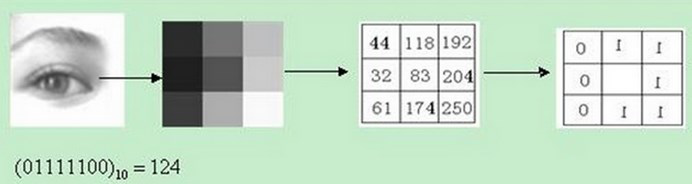
图 2.1
简单说举个例子一个33的区域,左边为原始的像素,右边为“描述子”。即把每一个边缘上的像素和中心位置比较,如果比中心位置较小写0,否则写1。然后从左上角开始写起,写成二进制串,再写成十进制数,即得到它的LBP值为124。
LBP从图像整体来看是一个“从大到小”的形式进行特征检测的。为什么呢?例如一幅图像,我们把它划分成若干个Block,然后在每个Block中划分成若干个Cell,在Cell中计算它的LBP值,如图2.2。假设
是一个Block,我们将一个Block展开成一个直方图的形式(X轴:LBP值;Y轴:Cell的数量)即为“描述子”。所以LBP是对一整幅图的描述。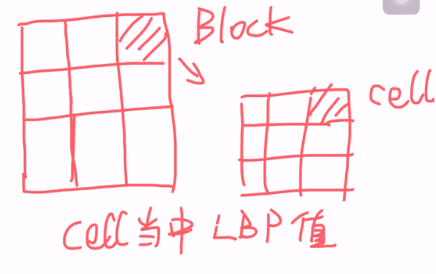
图 2.2
LBP三大要求:
(1)旋转不变性;
(2)尺度不变性;
(3)亮度不变性。
*1.1.3.2 使用Opencv中的LBP**
①首先准备数据集。数据集与SVM类似,对于SVM将是我们接下来要介绍的。分为车牌图片和非车牌图片。图像我们用的灰度图,分别放在pos和neg文件夹下。我用到的数据是pos:328个,neg:1000个。关于数量调整以后还要做测试。(一个模糊的规定是NEG为POS的3倍为最佳至于为什么,Opencv中应该会有解释)
②copy opencv安装目录下的opencv_traincascade.exe和opencv_createsamples.exe到一个指定文件夹,图2.4。
③生成路径。首先进入pos文件夹下新建一个get route.bat文件,文件内容为:dir /b > pos.txt。双击运行后会在pos文件夹下出现pos.txt文件,然后将pos.txt文件和get route.bat文件一同copy出来放到与pos文件夹同级目录下。接下来打开pos.txt将不是图像文件的行删去,只留下图像文件所在行(印象中删去了两行),并把文件保存成此种格式:
后面的130 30即是pos图像文件的宽和高。然后用同样的方法生成neg.txt,copy到与之相同文件夹下。不同的是neg.txt中的内容无需做修改,但要删除非图像文件名所在行(印象中也是两行)。接下来在同级目录下新建createsamples.bat。内容为:
opencv_createsamples.exe -info pos.txt -vec pos_LBP.vec -num 328 -w 130 -h 30
pause 双击后生成pos_LBP文件。(注意参数,要和你的参数相匹配)
④训练xml。在同一级目录下新建train.bat。内容为:
opencv_traincascade.exe -data data -vec pos_LBP.vec -bg neg.txt -numPos 328 -numNeg 1000 -featureType LBP -numStages 10 -w 130 -h 30 -minHitRate 0.9999 -maxFalseAlarmRate 0.5 -mode ALL
pause
(同样注意参数)
在这里参数就不做过多注释了。新建data文件夹。最终的文件个数见下图:
图 2.3 && 图 2.4
双击后运行训练。完成后可在data下生成xml文件。
上面的训练过程摘自自己的博客。当然那时还没有训练出很好的xml,同时也是第一次训练成功,也并非此时用到的文件。
此时,我们总结一下以上三种方法:方法1和方法2的最终结果得到的都是后选车牌图片,3得到的是XML文件。对于3,我们用CascadeClassifier 和 detectMultiScale加载读取XML文件并生成后选车牌图像。最终我们将分别可以得到车牌的候选图像。
关于三种方法的顺序优先级,我们首先使用的是颜色判断如果失败则进入Sobel方法如果失败则使用LBP方法。这三种方法可根据具体场景做出调优选择处理。我在这里做了一个小小的改进则是如果都没有判断出来则截掉图像的上四分之一,选取下四分之三作为RIO再进行判断,依此类推,如果RIO的高度小于某一数值则判断失败return &errorpicture;此方法有增加判断时间的风险,但在准确度和速度上需要做到一个很好的平衡还要具体场景具体分析。好了,以上三种方法即是得到有可能是车牌的图像:为“车牌粗定位”。最终确定车牌要用到“支持向量机”(support vector machine)将是我们第二部分的内容,接下来会做相应介绍。
1.2 车牌精定位
对于车牌精确定位,我们使用的是SVM即支持向量机,是机器学习中的监督学习算法。“支持向量机算法是诞生于统计学习界,同时在机器学习界大放光彩的经典算法。支持向量机算法从某种意义上来说是逻辑回归算法的强化:通过给予逻辑回归算法更严格的优化条件,支持向量机算法可以获得比逻辑回归更好的分类界线。但是如果没有某类函数技术,则支持向量机算法最多算是一种更好的线性分类技术。
但是,通过跟高斯“核”的结合,支持向量机可以表达出非常复杂的分类界线,从而达成很好的的分类效果。“核”事实上就是一种特殊的函数,最典型的特征就是可以将低维的空间映射到高维的空间。
我们如何在二维平面划分出一个圆形的分类界线?在二维平面可能会很困难,但是通过“核”可以将二维空间映射到三维空间,然后使用一个线性平面就可以达成类似效果。也就是说,二维平面划分出的非线性分类界线可以等价于三维平面的线性分类界线。于是,我们可以通过在三维空间中进行简单的线性划分就可以达到在二维平面中的非线性划分效果。
支持向量机是一种数学成分很浓的机器学习算法(相对的,神经网络则有生物科学成分)。在算法的核心步骤中,有一步证明,即将数据从低维映射到高维不会带来最后计算复杂性的提升。于是,通过支持向量机算法,既可以保持计算效率,又可以获得非常好的分类效果。因此支持向量机在90年代后期一直占据着机器学习中最核心的地位,基本取代了神经网络算法。直到现在神经网络借着深度学习重新兴起,两者之间才又发生了微妙的平衡转变。”
$~$——摘自计算机的潜意识博客《从机器学习谈起》
正如上面介绍的,SVM数学成分很浓本篇将对SVM做简单介绍,其数学原理和一些推导过程将不再赘述,具体可参考“模式识别”相关书籍,推荐科学出版社出版的《模式识别技术及其应用》在这里我们将结合Opencv中的SVM函数进行深入了解。
在QW-PR中,我们将得到的粗定位车牌图像一张一张的输入到SVM模型中判断是否为车牌。那么具体是如何实现的:
1.2.1 SVM训练
1.2.1.1 原始数据->学习数据(未标签)
“预处理步骤主要处理的是原始数据到学习数据的转换过程。原始数据(raw data),表示你一开始拿到的数据。这些数据的情况是取决你具体的环境的,可能有各种问题。学习数据(learn data),是可以被输入到模型的数据。
为了能够进入模型训练,必须将原始数据处理为学习数据,同时也可能进行了数据的筛选。比方说你有10000张原始图片,出于性能考虑,你只想用1000张图片训练,那么你的预处理过程就是将这10000张处理为符合训练要求的1000张。你生成的1000张图片中应该包含两类数据:真正的车牌图片和不是车牌的图片。如果你想让你的模型能够区分这两种类型。你就必须给它输入这两类的数据。”
1.2.1.2 (学习数据(未标签)->学习数据)
训练过程的第二步就是将未贴标签的数据转化为贴过标签的学习数据。我们所要做的工作只是将车牌图片放到一个文件夹里,非车牌图片放到另一个文件夹里。我们的目录结构为: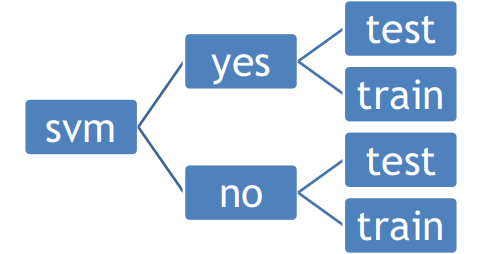
图 2.5 SVM训练目录
我们用到的yes-test数据是417,yes-train数据是6000;
我们用到的no-test数据是 990,no-train数据是9389。
1.2.1.3(训练数据)
放入训练器之前我们对图像做了二值化处理,这样有助于图像特征提取同时也很好的降低了训练时间。
关于参数设置我们不得不提到“核函数”。Opencv中的SVM共支持四种方式即:
①liner核,也就是无核。
②rbf核,使用的是高斯函数作为核函数。
③poly核,使用多项式函数作为核函数。
④sigmoid核,使用sigmoid函数作为核函数。
liner核,虽然名称带核,但它其实是无核模型,也就是没有使用核函数对数据进行转换。因此,它的分类效果仅仅比逻辑回归好一点。在EasyPR1.0版中,我们的SVM模型应用的是liner核。我们用的是图像的全部像素作为特征。
rbf核,会将输入数据的特征维数进行一个维度转换,具体会转换为多少维?这个等于你输入的训练量。假设你有500张图片,rbf核会把每张图片的数据转 换为500维的。如果你有1000张图片,rbf核会把每幅图片的特征转到1000维。这么说来,随着你输入训练数据量的增长,数据的维数越多。更方便在高维空间下的分类效果,因此最后模型效果表现较好。
既然选择SVM作为模型,而且SVM中核心的关键技巧是核函数,那么理应使用带核的函数模型,充分利用数据高维化的好处,利用高维的线型分类带来低维空间下的非线性分类效果。但是,rbf核的使用是需要条件的。
当你的数据量很大,但是每个数据量的维度一般时,才适合用rbf核。相反,当你的数据量不多,但是每个数据量的维数都很大时,适合用线型核。
在我们的训练样本中输入的训练数据总量有15389张,每个数据的特征用直方统计,共有172个维度。这个场景下,如果用rbf核的话,就会将每个数据的维度转化为与数据总数一样的数量,也就是15389的维度,可以充分利用数据高维化后的好处。但是,使用rbf核也有一个问题,那就是参数设置的问题。在rbf训练的过程中,参数的选择会显著的影响最后rbf核训练出模型的效果。因此必须对参数进行最优选择。
其中Opencv的SVM有个参数自动调优训练函数为:train_auto(),可以帮我们一步步调整参数,最后选择效果最好的那个参数(还不错)。
接下来就是训练样本了。有关SVM方法细节方面可能还有疏漏,后续如考虑到会将之补充上。经过SVM后我们即可得到归一化的车牌彩色图像,诸如此类:
图 2.6
以上步骤即完成了对车牌区域的的定位工作。目标检测在图像识别领域一直有新的算法出现,记录不断被刷新。正是因为这个原因,我们在选取算法时感觉既要知其然又要知其所以然,不然既赶不上不断变化的算法也不能很好地应用于现实场景中。找到所谓的车牌后我们需要对其进行处理,使之可以提取我们想要的信息。
部分代码:
////参数设置
SVM_params->setType(SVM::C_SVC);
SVM_params->setKernel(SVM::RBF); //核
SVM_params->setDegree(0);
SVM_params->setGamma(1);
SVM_params->setCoef0(0);
SVM_params->setC(1);
SVM_params->setNu(0);
SVM_params->setP(0);
SVM_params->setTermCriteria(TermCriteria(CV_TERMCRIT_ITER,2000,0.01));
////训练
qDebug()<<"train...";
Ptr<TrainData> tData =TrainData::create(trainingData,ROW_SAMPLE,classes);
SVM_params->trainAuto(tData,10, //自动训练参数
SVM::getDefaultGrid(SVM::C),
SVM::getDefaultGrid(SVM::GAMMA),
SVM::getDefaultGrid(SVM::P),
SVM::getDefaultGrid(SVM::NU),
SVM::getDefaultGrid(SVM::COEF),
SVM::getDefaultGrid(SVM::DEGREE),
true);
int g = SVM_params->getC();
float b = SVM_params->getGamma();
float c = SVM_params->getP();
float d = SVM_params->getNu();
float e = SVM_params->getCoef0();
float f = SVM_params->getDegree();
// SVM_params->train(tData);
SVM_params->save("E:\\BaiduNetdiskDownload\\ML\\save\\SVM_data.xml");
qDebug()<<"save ok!";
qDebug()<<"g:"<<g<<"b:"<<b<<"c:"<<c<<"d:"<<d<<"e:"<<e<<"f:"<<f;
Load *testD = new Load;
testD->getTestPlate();
return a.exec();1.3 车牌处理
1.3.1 颜色判断
判断车牌颜色我们使用的是HSV颜色空间。遍历像素点后分别计算像素点的HSV颜色值的总和,符合蓝色、黄色或其它颜色的我们分别判断:
if ((bluenum>yellownum)&&(bluenum>othernum))
{
ui->plateColorLabel->setText("蓝色车牌");
}
if ((yellownum>bluenum)&&(yellownum>othernum))
{
ui->plateColorLabel->setText("黄色车牌");
}
if ((othernum>yellownum)&&(othernum>bluenum))
{
ui->plateColorLabel->setText("其它颜色");
}1.3.2 预处理
为了便捷得到字符区域,灰度化—>二值化是必不可少的条件,这里需要注意二值化的时候如果阈值处理类型选择同一个,由于蓝色车牌和黄色车牌得到的结果正好相反,我们应该先做一下判断,如果为黄色则取反,这样才能使得到的效果一致。同时,由于车牌自身可能有铆钉等影响二值化效果,我们做了去除铆钉的处理,具体做法是:计算每行元素的阶跃数,如果小于某一值认为是柳丁所在行,将此行全部填0(涂黑)。到此为止,预处理过程完成,我们将得到一个二值化的车牌图像: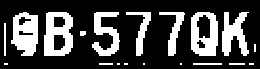
图 2.7
在这里,我想先介绍一下神经网络的相关情况:
BP神经网络(back propagation)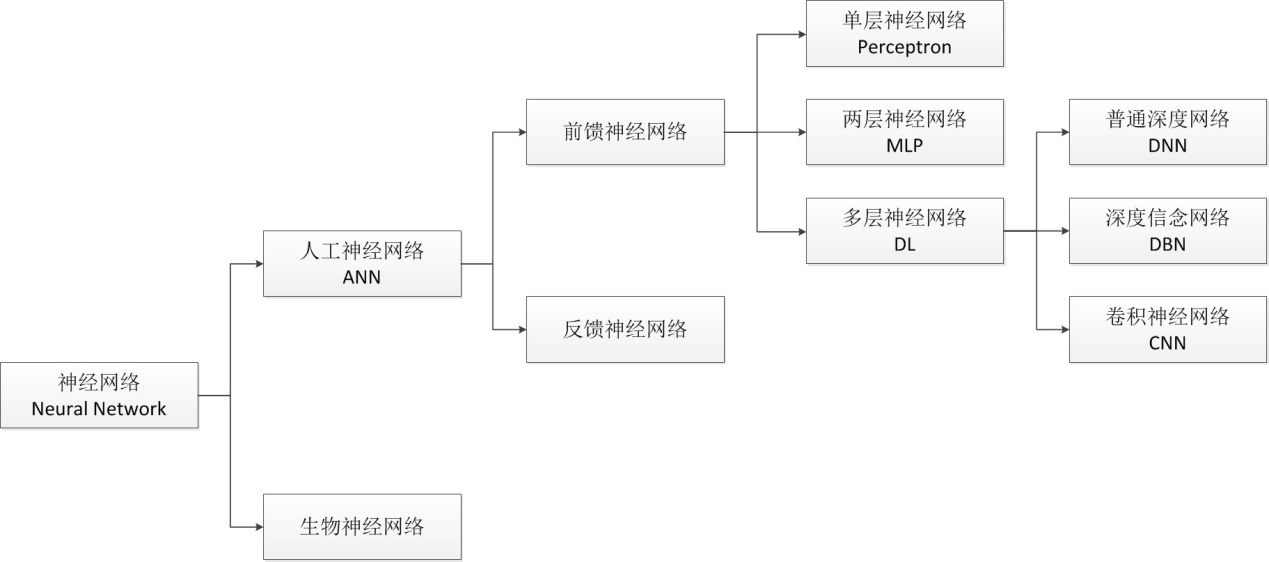
图 2.8 神经网络的简要族谱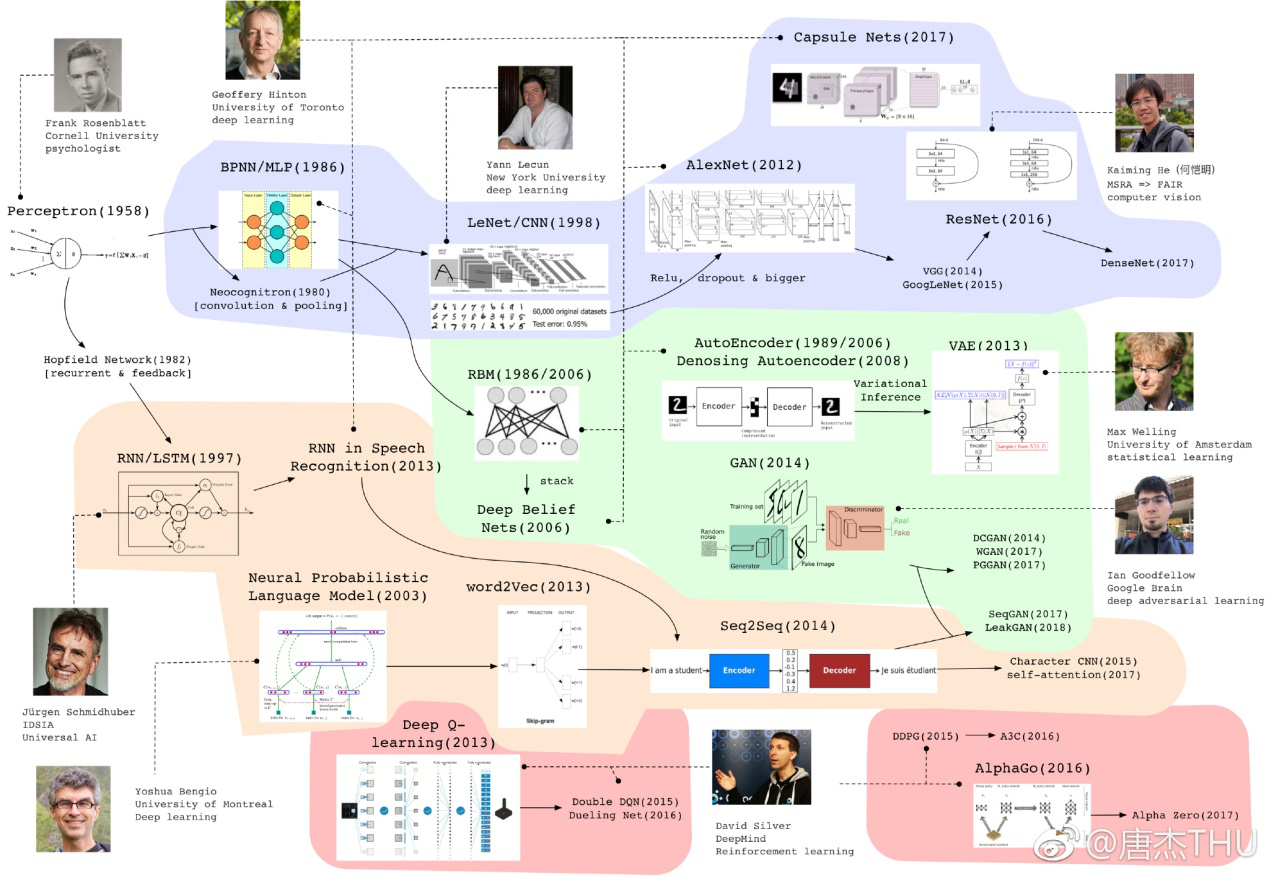
图 2.9 Deep Learning模型最近若干年的重要进展
在机器学习和相关领域,人工神经网络(人工神经网络)的计算模型灵感来自动物的中枢神经系统(尤其是脑),并且被用于估计或可以依赖于大量的输入和一般的未知近似函数。人工神经网络通常呈现为相互连接的“神经元”,它可以从输入的计算值,并且能够机器学习以及模式识别由于它们的自适应性质的系统。
例如,用于手写体识别的神经网络是由一组可能被输入图像的像素激活的输入神经元来限定。后进过加权,并通过一个函数(由网络的设计者确定的)转化,这些神经元的致动被上到其他神经元然后被传递。重复此过程,直到最后,一输出神经元被激活。这决定了哪些字符被读取。
像其他的从数据-神经网络认识到的机器学习系统方法已被用来解决各种各样的很难用普通的以规则为基础的编程解决的任务,包括计算机视觉和语音识别。这里我们主要说明一下我们使用到的BP神经网络。
说起神经网络,不得不从这幅图谈起: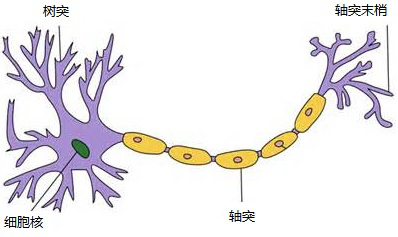
图 3.0 神经元
上图即是生物神经元组织的二维图。一个神经元通常具有多个树突,主要用来接受传入信息;而轴突只有一条,轴突尾端有许多轴突末梢可以给其他多个神经元传递信息。轴突末梢跟其他神经元的树突产生连接,从而传递信号。这个连接的位置在生物学上叫做“突触”。而神经网络则是在计算机中模拟这种结构,从而得到我们期望的效果。
1.3.3.1 多层感知器训练方法
训练多层感知器常用的一种方法是反向传播算法B-P,BP算法是一种用于前向多层网络的反向学习传播算法,其基本思想是:通过对组成前向多层网络的个人工神经元之间的连接权值进行不断的修改,从而使该前向神经网络能够将输入他的信息变换成所期望的输出信息,在修改个神经元的连接权值时,所依据的是该网络的实际输出与期望输出之差,将这一差值反向一层一层的传播,通过误差大小来决定权值的修改。
图 3.1 步调函数与阈值
当感知元把所有的输入的电信号结合在一起,计算出一个唯一的值Z之后,通过步调函数判断得到的Z值如果大于阈值则输出1,如果Z值小于阈值感知器则输出-1。在这里,我们把阈值改为了权重因子,把权重因子对应的信号固定为,于是、就加到了前面,运算出来后,判断Z值,如果Z值>0整个感知器输出1,如果小于0,则输出-1。
图 3.2 权重更新算法
即在原来的每一个分量上加上一个。人为调整学习率改进。例如:


图 3.3 权重更新示例-1,-2,-3
得到新的权重后在输入到模型中,再一次进行运算。同时我们的阈值也需要更新: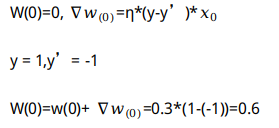
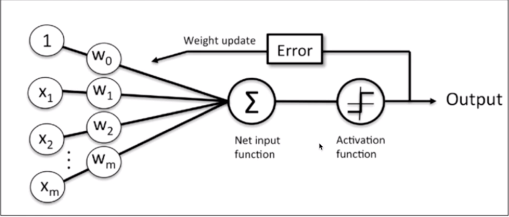
图 3.6 感知器步骤总结
适用范围:
线性可分割。
1.3.3.2 BP算法的原理
B-P算法由前向传播和反向传播组成。
前向传播用于对前向网络进行计算,即对某一输入信息,经过在网络中一层一层传播,直至到达输出层,求出他的输出结果;反向传播用于逐层传递误差,通过比较实际输出与期望输出的误差,逐层反向传播,并修改神经元间的连接权值,以使网络对输入信息经过计算后所得到的输出能达到期望的误差要求。
1.3.3.3 算法步骤
在这里简单写一下算法步骤:如需了解更多请参考相关书籍:
①变量定义
②网络初始化
③随机选取第K个样本及对应期望输出
④计算隐藏层个神经元的输入和输出(前向传播)
⑤利用网络期望输出和实际输出计算误差函数对输出层各神经元的偏导数
⑥利用隐藏层到输出层的连接权值,输出层的偏导和隐藏层的输出计算误差函数对隐藏层各神经元的偏导数
⑦利用输出层个神经元的偏导和隐藏层各神经元的输出修正连接权值
⑧利用输出层个神经元的偏导和输入层各神经元的输入修正连接权值
⑨计算全局误差(算法终止条件判断)
⑩判断算法结束条件
1.3.3.4 算法优缺点
一般来说具有以下优点:
(1)非线性映射能力
(2)自学习和自适应能力
(3)一定的泛化能力
(4)容错能力
缺点:
(1)收敛速度慢
(2)局部极小问题
(3)神经网络结构选择不一
(4)有旧样本遗忘现象
关于神经网络先介绍到这里。然而在我们使用Opencv的时候调用相应函数即可使用行对应的神经网络。我们的QW-PR通过训练字符样本(汉字、数字+字母)最终判断所产成字符是什么。要想得到我们想要的字符我把车牌字符区域分成了两类:简称区和数字字母区。
1.3.4 字符分割(并归一化)
得到二值化的车牌图像后我们同样用取轮廓、加外接矩形的方式来分割字符。但是在分割时会遇到有的汉字字符会被分割成两部分(上下或左右),鉴于车牌中每一个字符的面积和间距基本相同,我们这里用到了先找出第二个字符即市级字符,然后通过框出的矩形左移一定间距来框选出第一个即省级简称字符,其它后续字符根据间距不同统一框选出排序即可。需要注意的是,由于测试在此阶段出现过bug,1字符在代码中有一个特殊的处理(保一处理)。具体详细请查看相应代码。
1.3.5 ANN网络识别
Opencv2.X与Opencv3.X调用ANN不太相同,我们使用的是3层网络,这里给出部分代码:
Ptr
Mat layerSizes = (Mat_
bp->setLayerSizes(layerSizes);
bp->setActivationFunction(ANN_MLP::SIGMOID_SYM,1,1);
bp->setTrainMethod(ANN_MLP::BACKPROP,0.1,0.1);
bp->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER + TermCriteria::EPS,30000,0.0001)); //设置迭代终止准则
bp->setBackpropWeightScale(0.1);
bp->setBackpropMomentumScale(0.1);
Ptr
调用部分:
cv::Ptrcv::ml::ANN_MLP bp = cv::ml::ANN_MLP::create();
bp = cv::ml::ANN_MLP::load(“E:\BaiduNetdiskDownload\pnfwV_1.0\xml\Zh_data.xml”);
cv::Mat test_temp;
cv::resize(src,test_temp,cv::Size(image_cols,image_rows),(0,0),(0,0),CV_INTER_AREA);
cv::threshold(test_temp,test_temp,0,255,CV_THRESH_OTSU+CV_THRESH_BINARY);
cv::Mat_<float>sampleMat(1,image_cols*image_rows);
for(int i = 0; i<image_cols*image_rows; ++i)
{
sampleMat.at<float>(0,i) = (float)test_temp.at<uchar>(i/8,i%8); //将test数据(unchar)copy到sampleMat(float)中,图像特征
}
cv::Mat responseMat;
bp->predict(sampleMat,responseMat); //过调用predict函数,我们得到一个输出向量,它是一个1*nClass的行向量,识别
/*每一列说明它与该类的相似程度(0-1之间),也可以说是置信度*/ 本篇重点讲解方法和应用,所以代码和公式也就很少(很多基本忽略掉了)
通过以上步骤可最终得到相应的识别结果: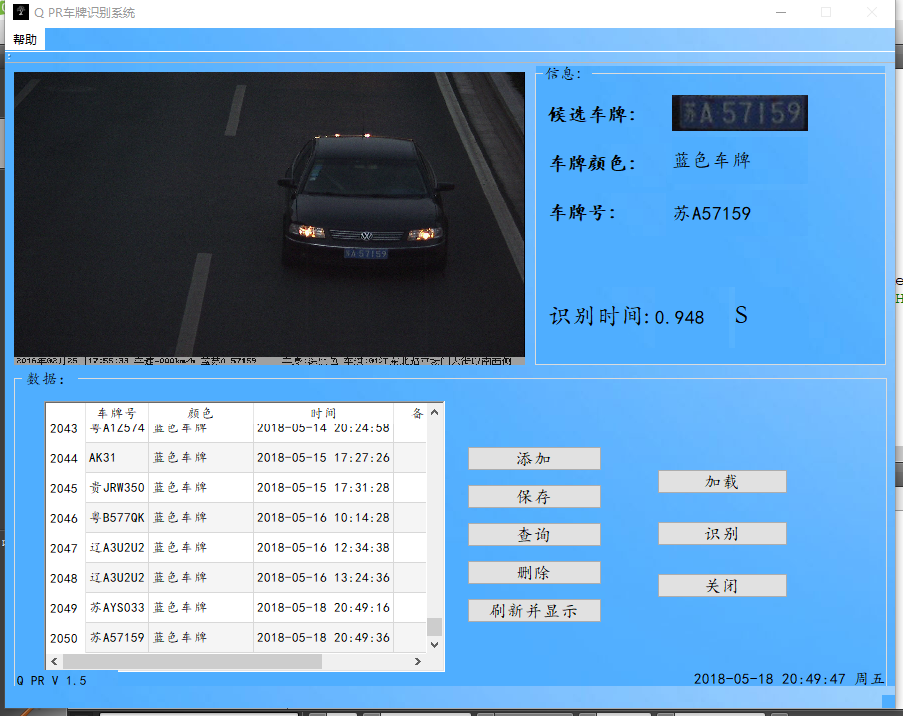
图 3.7
以上并没有对数据库做相应说明。
不足之处为:
(1)对偏斜程度较大的图像识别不够准确
(2)ANN训练优化做的不够好
(3)统计信息不够完善,例如识别精确度、训练测试准确率……
(4)多线程使用体验会更好
QW-PR的简要流程就是这些。正如开篇介绍的成为受益者的的同时也要成为施益者,希望本篇能对车牌识别的小白带来帮助。
相关参考:
(1)《模式识别技术及其应用》杨帮华 李昕 杨磊 马世伟 著
(2)计算机的潜意识博客园相关博客
Opencv带函数手册
$$祥义$$原文写于2017年



